Governance for
Domain-Specific AI Systems
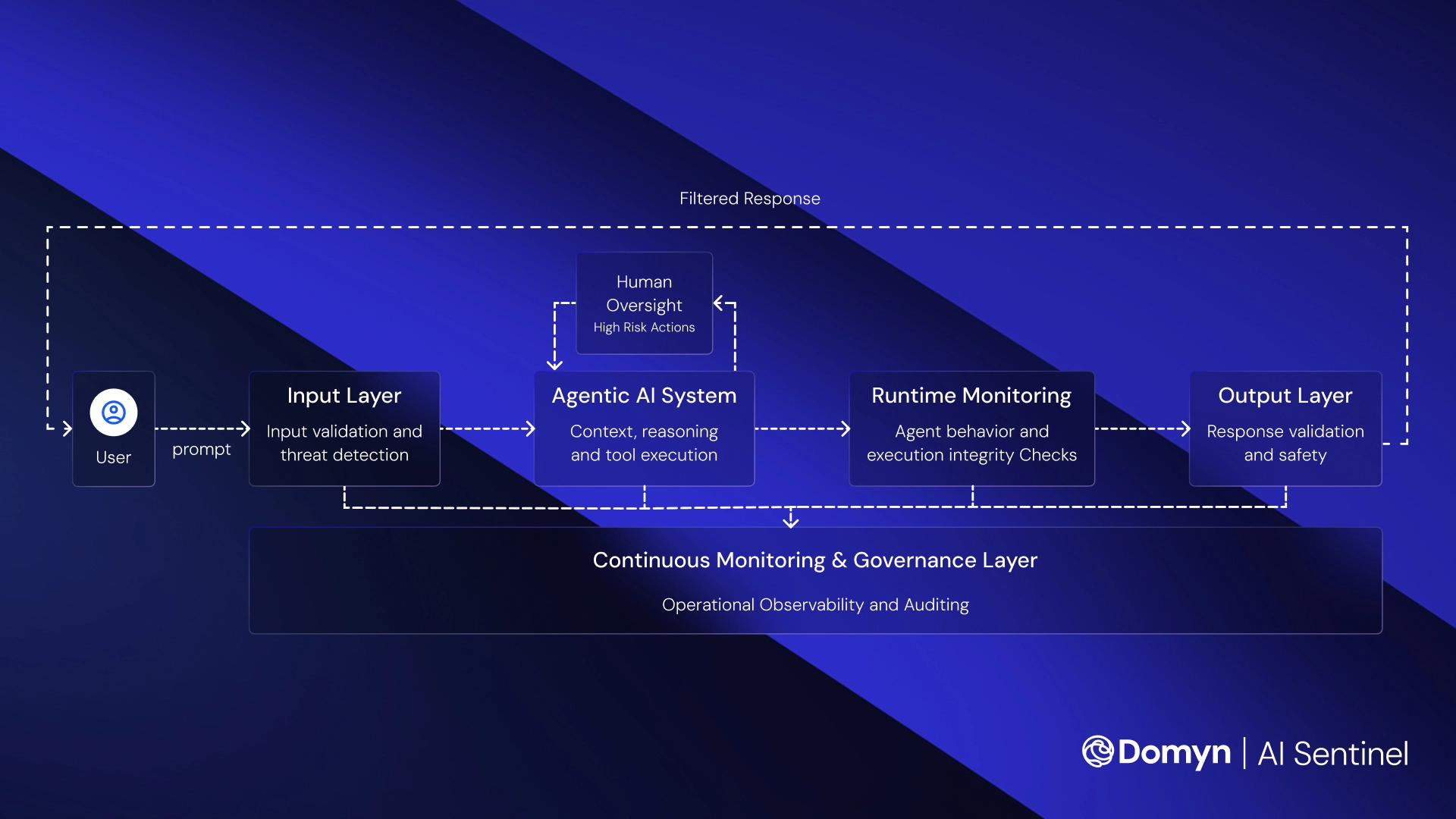
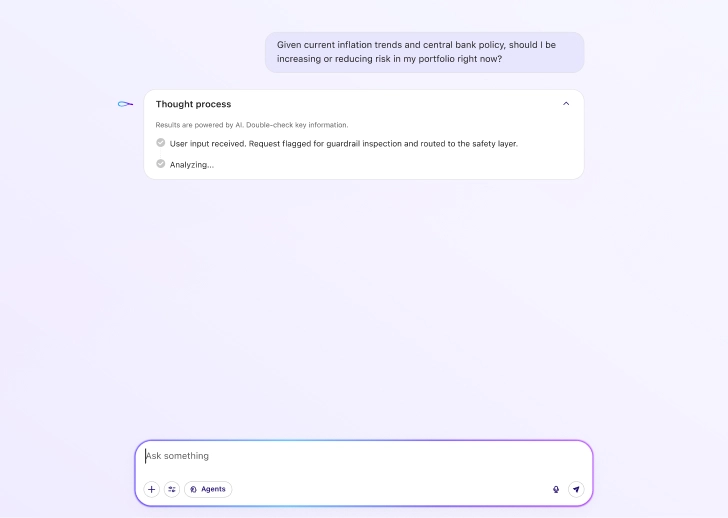
AI Sentinel continuously monitors model behavior in production environments, detects hallucinations, bias, and unsafe outputs, and enforces safeguards aligned with the operational and regulatory realities of each domain.