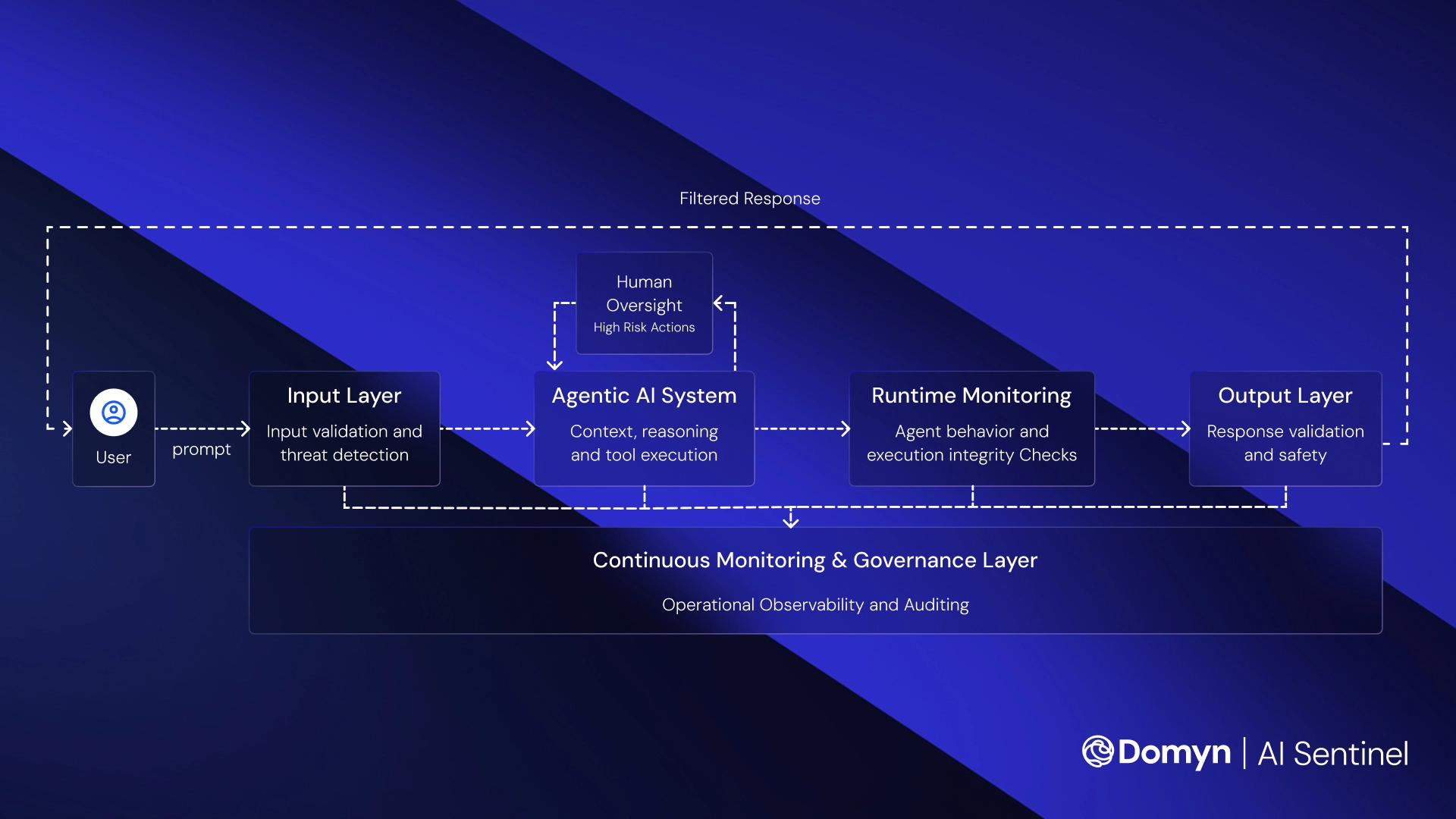
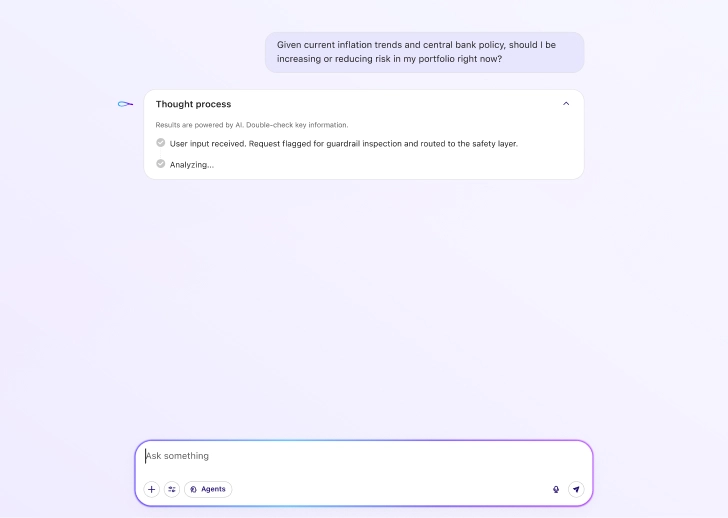
Governance per sistemi AI verticali
AI Sentinel monitora continuamente il comportamento dei modelli in ambienti di produzione, rileva allucinazioni, bias e contenuti non sicuri, e applica salvaguardie allineate alle esigenze operative e normative di ogni settore.